

Still on My First ML Project that Uses Time-series Data - Data Cleaning


This is the second part of this series. Its a series around a project I introduced here. This part talks about further data cleaning achieved
In the previous post, I 'discovered' and became aware of the fact that I was dealing with time-series data which refined my mindset about the nature of the data etc. I also created an additional feature called duration which was obtained from the existing start and end time series.
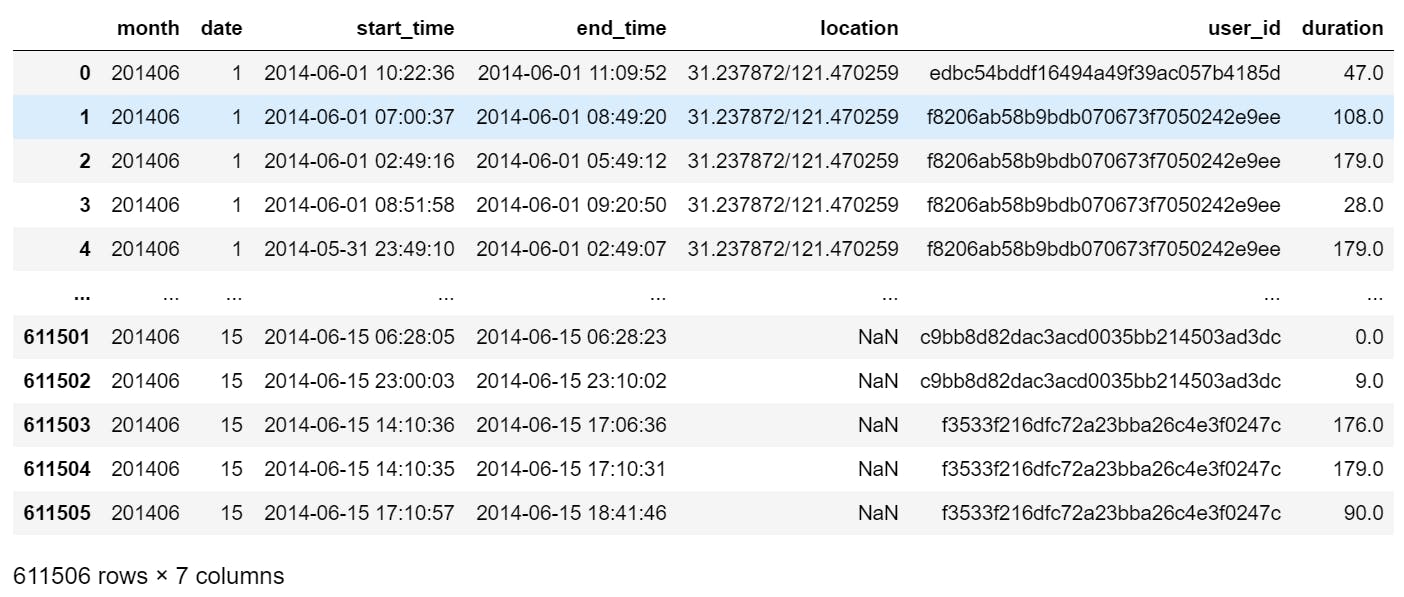
I mentioned that there were some missing values within the data that I wasn't sure whether to replace by data imputation, or get rid of entirely.
The missing values were only in one of the columns, the location column as seen vaguely in the image above. However to really be sure, I checked the missing values by:
#checking the missing values
data.isna().sum()
This produced the following output:
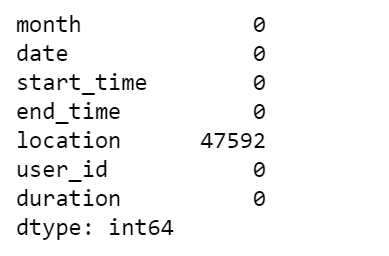
The location column has about 47000 missing values.
So, we have about 47000 examples with missing values making up approximately 7.7% of the total dataset.
A rule of thumb for determining whether to delete examples with missing data or to use data imputation methods is to first check that the missing data is 5% or less than the total data available in the dataset.
In my case, this is not so. Therefore, I opted to delete the examples with missing values.
- I converted the location series to strings even though it has numerical values. This was informed by the knowledge of the domain and the nature of the data (longitudes and latitudes).
data['location']=data['location'].apply(lambda v: str(v) if str(v) != 'nan' else None).tolist()
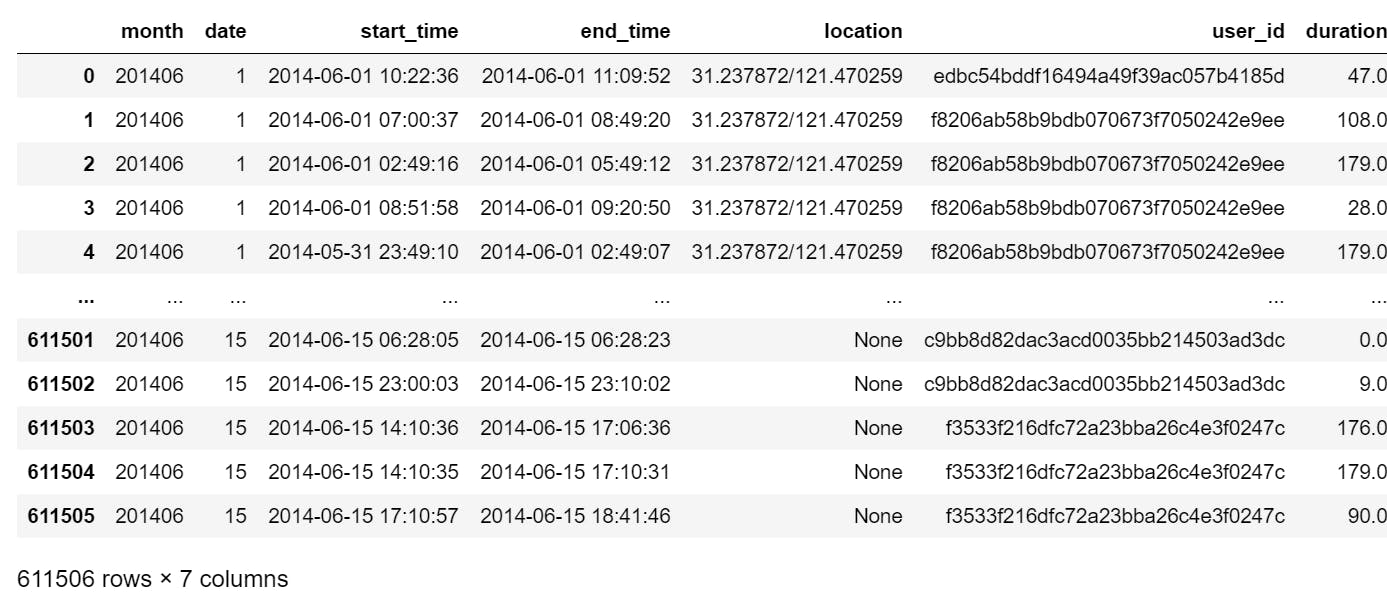
The NaNs were replaced by None values as expected.
- I converted the dataset into tuples and looped through while checking for empty strings or NaSs.
blank = []
nas = []
for index, month, date, start_time, end_time,location, user_id, duration in data.itertuples():
if type(location)==str:
if location.isspace():
blank.append(index)
else:
nas.append(index)
- I found 0 blank spaces and the missing values(now stored in the list called nas) were 47592 in total. Then I dropped them from the dataset.
data.drop(nas, inplace=True)
- checking for missing values again produced:
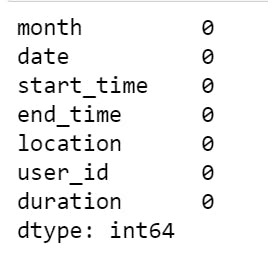
- The total examples in the dataset reduced to about 564000
Overall, I learnt a lot of new things while I was trying to clean up the missing values from this dataset. I learnt about GAN(generative adversarial networks) and how I might apply them in cases where I don't have access to alot of data that I require. I learnt about data imputation and the use of measures of central tendency(mean median and mode) for numeric and categorical data imputation decision making.
I discovered jordan harrod's youtube channel, this very helpful piece by okoh anita. I discovered DJ sankar and this article about categorical data transformation and encoding which in fact, is more of what i will be doing next.
I will be performing more feature engineering and transformation and encoding of the features to then be able to see the data distribution of each feature and finally, (hopefully) identify the label that I am interested in.
Can't wait!🤸🏾♀️